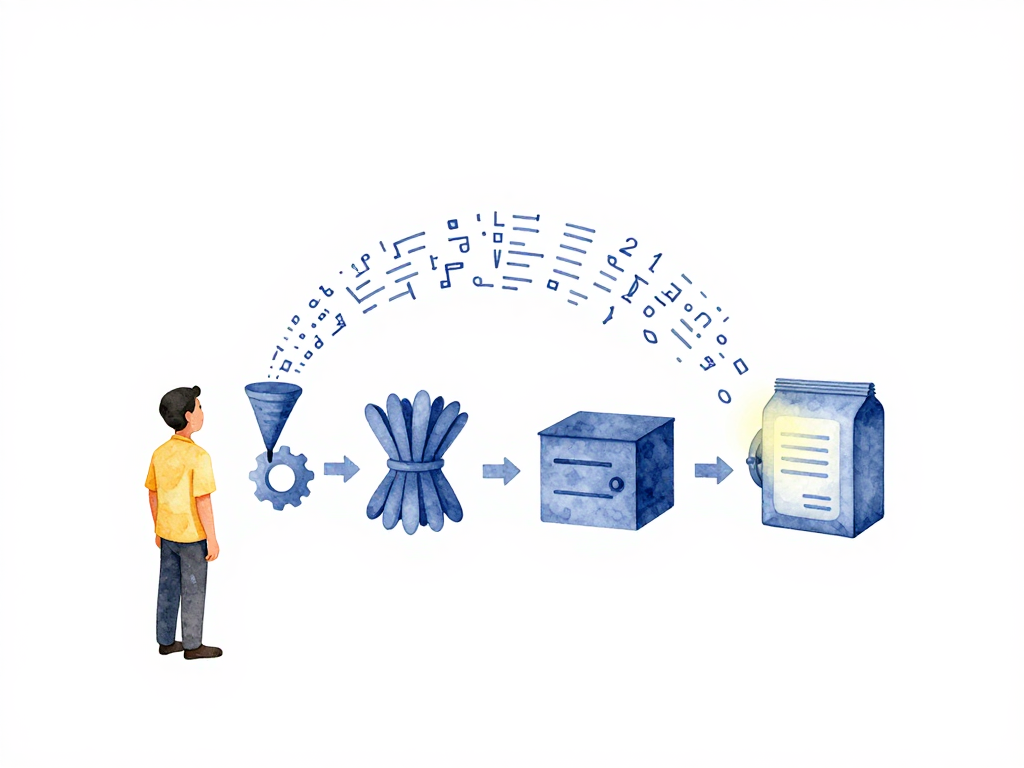
Du code au package exécutable : ce qui se passe avant le déploiement
Vous venez de terminer une nouvelle fonctionnalité. Le code compile en local, les tests passent sur votre machine, et vous êtes confiant. Mais quand vous poussez le code et tentez de déployer, quelque chose casse. Le serveur se plaint d'une bibliothèque manquante. Le binaire plante car il a été compilé sur une version différente de l'OS. Le script de déploiement ne trouve pas le bon artefact.
Cette situation est plus courante que la plupart des équipes ne l'admettent. L'écart entre "le code fonctionne sur ma machine" et "le code tourne en production" est rempli d'étapes faciles à négliger. Comprendre ce qui se passe entre l'écriture du code et l'obtention d'un package déployable est essentiel pour tout ingénieur impliqué dans la livraison de logiciels.
Qu'est-ce qu'un build, vraiment ?
Quand un développeur écrit du code, ce code n'est pas encore prêt à être exécuté sur un serveur. Il doit être transformé en quelque chose d'exécutable. Ce processus de transformation s'appelle un build. Le résultat d'un build s'appelle un artefact.
Les artefacts se présentent sous deux formes courantes :
- Fichiers binaires : Un fichier exécutable unique que le système d'exploitation peut lancer directement. Pensez à un programme Go compilé ou à un fichier JAR Java.
- Images conteneur : Un package qui contient le binaire plus tout ce dont il a besoin pour fonctionner : bibliothèques, fichiers de configuration, variables d'environnement et l'exécution elle-même. Les images conteneur sont utilisées lors du déploiement dans des environnements comme Docker ou Kubernetes.
Le choix entre binaire et image conteneur dépend de votre infrastructure de déploiement. Les conteneurs offrent plus de cohérence entre les environnements, tandis que les binaires sont plus légers et démarrent plus vite. Dans les deux cas, l'objectif est le même : produire un package autonome qui peut être déployé de manière fiable.
Les quatre étapes de la construction
Chaque service backend, quel que soit le langage ou le framework, passe par ces étapes. Parcourons-les une par une.
Le diagramme ci-dessous montre le pipeline de build complet, du code source à l'artefact stocké.
Étape 1 : Compilation
Si votre code est écrit dans un langage compilé comme Go, Java, Rust ou C++, il doit être compilé en code machine ou bytecode avant de pouvoir s'exécuter. Les langages comme Python, Node.js ou Ruby sautent cette étape car ils sont interprétés à l'exécution.
Le détail critique ici est la cohérence de l'environnement. Si vous compilez sur le portable d'un développeur puis copiez le binaire sur un serveur de production, vous risquez des problèmes de compatibilité. Le serveur de production pourrait avoir une version différente du système d'exploitation, des bibliothèques système différentes ou une architecture CPU différente. Compilez toujours dans un environnement qui correspond le plus possible à votre cible de production.
Pour les langages interprétés, la compilation n'est pas nécessaire, mais vous devez quand même préparer l'environnement d'exécution. Cela mène à l'étape suivante.
Étape 2 : Regroupement des dépendances
Les applications backend ne fonctionnent presque jamais avec leur seul code. Elles dépendent de bibliothèques externes pour l'accès à la base de données, la gestion HTTP, l'authentification, la journalisation et des dizaines d'autres préoccupations. Ces dépendances doivent être collectées et empaquetées avec votre code.
Le mécanisme exact dépend de votre écosystème de langage :
- Python : Exécutez
pip installet collectez tous les packages dans un dossier spécifique ou un environnement virtuel. - Node.js : Exécutez
npm installet assurez-vous que le répertoirenode_modulesest complet. - Java : Les dépendances sont regroupées dans un fichier JAR ou WAR pendant le processus de build.
- Go : Les dépendances sont compilées directement dans le binaire, donc aucun regroupement séparé n'est nécessaire.
Le principe est simple : quand l'artefact s'exécute sur un serveur, tout ce dont il a besoin doit déjà être à l'intérieur. Personne ne devrait avoir à installer manuellement des dépendances pendant le déploiement. C'est une recette pour l'incohérence et l'échec.
Étape 3 : Création de l'artefact
Maintenant, vous devez produire le package final. Si votre équipe utilise des conteneurs, cela signifie construire une image Docker à l'aide d'un Dockerfile. L'image contient le binaire compilé ou le code de l'application, toutes les dépendances, la configuration de base et la commande pour démarrer l'application.
Voici un exemple pratique d'un Dockerfile multi-étapes qui compile une application Go et produit une image conteneur minimale :
# Étape 1 : Compilation et regroupement des dépendances
FROM golang:1.21-alpine AS builder
WORKDIR /app
COPY go.mod go.sum ./
RUN go mod download
COPY . .
RUN CGO_ENABLED=0 GOOS=linux go build -o /app/server .
# Étape 2 : Création de l'artefact final
FROM alpine:3.19
RUN apk --no-cache add ca-certificates tzdata
COPY --from=builder /app/server /server
EXPOSE 8080
CMD ["/server"]
Si votre équipe n'utilise pas de conteneurs, le résultat du build est un fichier binaire ou un dossier compressé qui peut être copié directement sur le serveur. Les binaires sont plus simples et plus rapides à déployer, mais ils offrent moins d'isolation et de portabilité que les images conteneur.
Dans les deux cas, l'artefact doit être immuable. Une fois construit, il ne doit pas être modifié. Tout changement signifie un nouveau build et un nouvel artefact. Cela garantit que ce que vous avez testé est exactement ce que vous déployez.
Étape 4 : Stockage de l'artefact
L'artefact terminé a besoin d'un emplacement permanent où les processus de déploiement peuvent y accéder. Cet emplacement de stockage s'appelle un registre ou un référentiel.
- Les images conteneur vont dans un registre de conteneurs : Docker Hub, Amazon ECR, Google Artifact Registry, ou des options auto-hébergées comme Harbor.
- Les fichiers binaires vont dans un référentiel d'artefacts : Nexus, Artifactory, ou même un stockage d'objets comme S3.
Chaque artefact doit avoir un identifiant unique. C'est généralement un numéro de version, un hash de commit Git, ou une combinaison des deux. Avec des identifiants uniques, votre équipe peut toujours retracer quelle version du code est en cours d'exécution en production. Quand quelque chose tourne mal, vous pouvez regarder l'ID de l'artefact et savoir exactement ce qui a été déployé.
Pourquoi l'automatisation est importante
Chacune de ces étapes doit se produire de la même manière à chaque fois. Si vous construisez manuellement, vous finirez par sauter une étape, utiliser la mauvaise version de dépendance, ou compiler sur la mauvaise machine. Le résultat est un artefact qui se comporte différemment de ce que vous attendiez.
Un pipeline CI automatise l'ensemble du processus. Il se déclenche à chaque changement de code, exécute les étapes de build en séquence et stocke l'artefact avec un identifiant approprié. Le pipeline garantit que chaque artefact est construit de la même manière, avec les mêmes outils, dans le même environnement.
Cette cohérence est ce qui rend les déploiements prévisibles. Lorsque vous déployez un artefact provenant d'un pipeline CI, vous savez exactement ce que vous obtenez. Il n'y a pas de surprises dues à des étapes manuelles ou à des différences d'environnement.
Liste de contrôle pratique pour votre processus de build
Avant de configurer votre pipeline de build, vérifiez ces points :
- L'environnement de build correspond à l'environnement de production (version de l'OS, bibliothèques système, architecture).
- Toutes les dépendances sont déclarées explicitement (fichiers de verrouillage, requirements.txt, go.mod, etc.).
- L'artefact est construit exactement une fois par changement de code et stocké de manière immuable.
- Chaque artefact a un identifiant unique et traçable (tag de version ou hash de commit).
- Le processus de build s'exécute automatiquement à chaque push ou merge sur la branche principale.
- Le registre d'artefacts est accessible au processus de déploiement sans intervention manuelle.
Et ensuite
Une fois l'artefact prêt et stocké, la question suivante est de savoir s'il est sûr à déployer. C'est là que les tests automatisés et l'analyse de sécurité entrent en jeu. Les tests unitaires, les tests d'intégration, les analyses de vulnérabilités et d'autres vérifications sont exécutés sur l'artefact avant qu'il n'atteigne la production.
Mais aucun de ces contrôles n'a d'importance si le build lui-même est cassé. Un processus de build fiable est le fondement de chaque pipeline CI/CD. Sans lui, vous déployez des suppositions, pas du logiciel.
À retenir : Un build n'est pas seulement une étape technique. C'est le moment où le code devient un actif déployable. Traitez-le avec la même rigueur que vous appliquez aux systèmes de production. Automatisez-le, standardisez-le et rendez chaque artefact traçable. Vous-même, en train de déboguer un problème de production à 2 heures du matin, vous en remercierez.