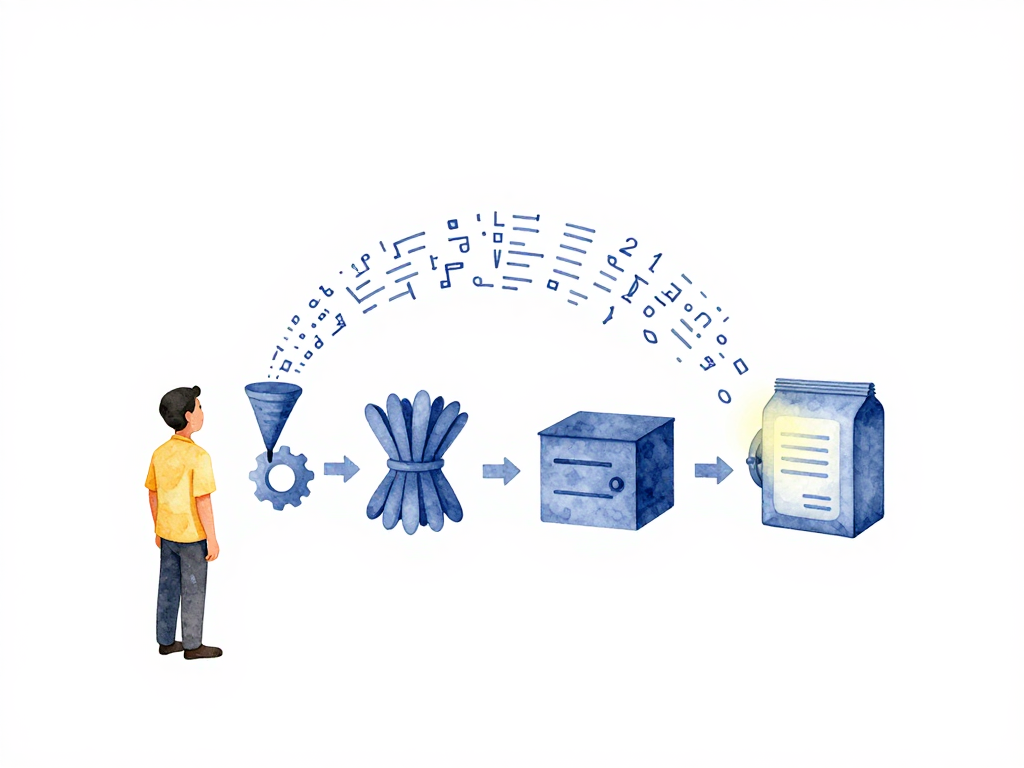
От кода к исполняемому пакету: что происходит до деплоя
Вы только что закончили писать новую фичу. Код компилируется локально, тесты проходят на вашей машине, и вы уверены в результате. Но когда вы пушите код и пытаетесь выполнить деплой, что-то ломается. Сервер жалуется на отсутствующую библиотеку. Бинарник падает, потому что был скомпилирован под другую версию ОС. Скрипт деплоя не может найти нужный артефакт.
Эта ситуация встречается чаще, чем принято признавать. Разрыв между «код работает на моей машине» и «код работает в продакшене» заполнен шагами, которые легко упустить. Понимание того, что происходит между написанием кода и получением готового к деплою пакета, необходимо любому инженеру, участвующему в доставке ПО.
Что такое сборка на самом деле?
Когда разработчик пишет код, этот код ещё не готов к запуску на сервере. Его нужно преобразовать в нечто исполняемое. Этот процесс преобразования называется сборкой (build). Результат сборки называется артефактом.
Артефакты бывают двух распространённых типов:
- Бинарные файлы: Один исполняемый файл, который операционная система может запустить напрямую. Например, скомпилированная программа на Go или JAR-файл Java.
- Контейнерные образы: Пакет, содержащий бинарник и всё необходимое для его работы: библиотеки, файлы конфигурации, переменные окружения и сам рантайм. Контейнерные образы используются при деплое в Docker или Kubernetes.
Выбор между бинарником и контейнерным образом зависит от вашей инфраструктуры деплоя. Контейнеры обеспечивают большую согласованность между окружениями, тогда как бинарники легче и запускаются быстрее. В любом случае цель одна: получить самодостаточный пакет, который можно надёжно развернуть.
Четыре этапа сборки
Любой backend-сервис, независимо от языка или фреймворка, проходит через эти этапы. Давайте разберём их по порядку.
Диаграмма ниже показывает полный пайплайн сборки от исходного кода до сохранённого артефакта.
Этап 1: Компиляция
Если ваш код написан на компилируемом языке, таком как Go, Java, Rust или C++, его необходимо скомпилировать в машинный код или байт-код перед запуском. Языки вроде Python, Node.js или Ruby пропускают этот шаг, так как они интерпретируются во время выполнения.
Ключевой момент здесь — согласованность окружения. Если вы компилируете на ноутбуке разработчика, а затем копируете бинарник на продакшен-сервер, вы рискуете получить проблемы совместимости. На продакшен-сервере может быть другая версия ОС, другие системные библиотеки или другая архитектура процессора. Всегда компилируйте в окружении, максимально близком к целевому продакшену.
Для интерпретируемых языков компиляция не нужна, но всё равно требуется подготовить среду выполнения. Это подводит нас к следующему этапу.
Этап 2: Упаковка зависимостей
Backend-приложения почти никогда не работают только с собственным кодом. Они зависят от внешних библиотек для доступа к базам данных, обработки HTTP, аутентификации, логирования и десятков других задач. Эти зависимости необходимо собрать и упаковать вместе с вашим кодом.
Конкретный механизм зависит от вашей языковой экосистемы:
- Python: Выполните
pip installи соберите все пакеты в определённую папку или виртуальное окружение. - Node.js: Выполните
npm installи убедитесь, что каталогnode_modulesполон. - Java: Зависимости упаковываются внутрь JAR или WAR-файла в процессе сборки.
- Go: Зависимости компилируются непосредственно в бинарник, поэтому отдельная упаковка не требуется.
Принцип прост: когда артефакт запускается на сервере, всё, что ему нужно, уже должно быть внутри. Никто не должен вручную устанавливать зависимости во время деплоя. Это верный путь к неконсистентности и сбоям.
Этап 3: Создание артефакта
Теперь нужно создать финальный пакет. Если ваша команда использует контейнеры, это означает сборку Docker-образа с помощью Dockerfile. Образ содержит скомпилированный бинарник или код приложения, все зависимости, базовую конфигурацию и команду для запуска приложения.
Вот практический пример многостадийного Dockerfile, который компилирует Go-приложение и создаёт минимальный контейнерный образ:
# Stage 1: Компиляция и упаковка зависимостей
FROM golang:1.21-alpine AS builder
WORKDIR /app
COPY go.mod go.sum ./
RUN go mod download
COPY . .
RUN CGO_ENABLED=0 GOOS=linux go build -o /app/server .
# Stage 2: Создание финального артефакта
FROM alpine:3.19
RUN apk --no-cache add ca-certificates tzdata
COPY --from=builder /app/server /server
EXPOSE 8080
CMD ["/server"]
Если ваша команда не использует контейнеры, результатом сборки будет бинарный файл или сжатая папка, которую можно скопировать напрямую на сервер. Бинарники проще и быстрее в деплое, но они обеспечивают меньшую изоляцию и переносимость по сравнению с контейнерными образами.
В любом случае артефакт должен быть неизменяемым (immutable). После сборки его нельзя модифицировать. Любое изменение означает новую сборку и новый артефакт. Это гарантирует, что то, что вы тестировали, — это именно то, что вы разворачиваете.
Этап 4: Хранение артефакта
Готовому артефакту нужно постоянное место, откуда процессы деплоя смогут его получить. Такое хранилище называется реестром (registry) или репозиторием.
- Контейнерные образы помещаются в контейнерный реестр: Docker Hub, Amazon ECR, Google Artifact Registry или self-hosted решения вроде Harbor.
- Бинарные файлы помещаются в репозиторий артефактов: Nexus, Artifactory или даже объектное хранилище вроде S3.
Каждый артефакт должен иметь уникальный идентификатор. Обычно это номер версии, хеш Git-коммита или их комбинация. С уникальными идентификаторами ваша команда всегда может отследить, какая версия кода работает в продакшене. Когда что-то идёт не так, вы можете посмотреть на ID артефакта и точно узнать, что было развёрнуто.
Почему автоматизация важна
Каждый из этих этапов должен выполняться одинаково каждый раз. Если вы собираете вручную, рано или поздно вы пропустите шаг, используете не ту версию зависимости или скомпилируете не на той машине. В результате артефакт будет вести себя не так, как ожидалось.
CI-пайплайн автоматизирует весь процесс. Он запускается при каждом изменении кода, последовательно выполняет этапы сборки и сохраняет артефакт с правильным идентификатором. Пайплайн гарантирует, что каждый артефакт собирается одинаково, одними и теми же инструментами, в одном и том же окружении.
Эта согласованность делает деплои предсказуемыми. Когда вы разворачиваете артефакт из CI-пайплайна, вы точно знаете, что получаете. Никаких сюрпризов от ручных шагов или различий в окружении.
Практический чек-лист для процесса сборки
Прежде чем настраивать пайплайн сборки, проверьте следующие пункты:
- Окружение сборки соответствует продакшен-окружению (версия ОС, системные библиотеки, архитектура).
- Все зависимости явно объявлены (lock-файлы, requirements.txt, go.mod и т.д.).
- Артефакт собирается ровно один раз на каждое изменение кода и хранится неизменным.
- Каждый артефакт имеет уникальный отслеживаемый идентификатор (тег версии или хеш коммита).
- Процесс сборки запускается автоматически при каждом пуше или слиянии в основную ветку.
- Реестр артефактов доступен процессу деплоя без ручного вмешательства.
Что дальше
Когда артефакт готов и сохранён, следующий вопрос — безопасно ли его разворачивать. Здесь в дело вступают автоматическое тестирование и сканирование безопасности. Модульные тесты, интеграционные тесты, сканеры уязвимостей и другие проверки выполняются над артефактом до того, как он попадёт в продакшен.
Но ни одна из этих проверок не имеет значения, если сама сборка сломана. Надёжный процесс сборки — это фундамент любого CI/CD-пайплайна. Без него вы разворачиваете не софт, а гадание.
Вывод: Сборка — это не просто технический шаг. Это момент, когда код превращается в развёртываемый актив. Относитесь к нему с той же строгостью, что и к продакшен-системам. Автоматизируйте его, стандартизируйте и делайте каждый артефакт отслеживаемым. Ваше будущее «я», отлаживающее проблему в продакшене в 2 часа ночи, скажет вам спасибо.